

Clustering: The Foundation of Scalability
Clustering is the core mechanism that enables scalability within the platform. It allows multiple physical nodes to operate as a single logical service, distributing traffic across nodes and preventing any single instance from becoming a bottleneck.
While clustering is commonly associated with distributed environments, it is important to note that not all cluster modes are distributed. For example, Local mode keeps all data on a single machine and is intended for standalone deployments.
By configuring clustering properly, the platform gains redundancy, reliability, and the ability to scale as traffic demands increase.
To transform a standalone instance into a high-availability cluster, the following parameters must be configured.

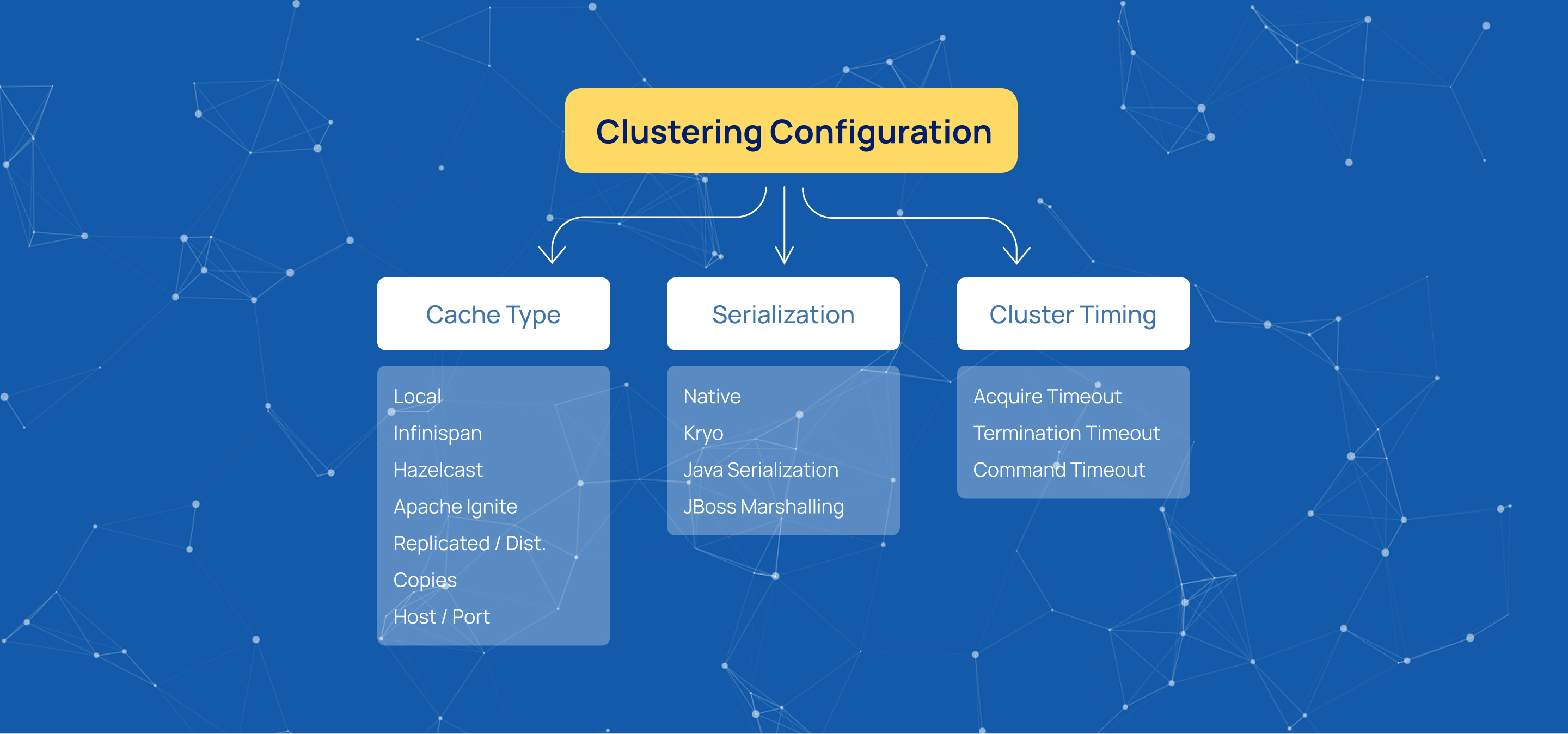
Cache Type
The Cache Type determines the clustering logic used by the environment. Depending on the selected type, the interface dynamically displays different configuration fields.
Local
Used for standalone instances only.
Provides no clustering and includes the minimal configuration set.
Infinispan
An open-source In-Memory Data Grid (IMDG) built directly into Java memory. By default, it typically uses UDP multicast communication to discover cluster nodes.
When Infinispan is selected, additional configuration fields become available.
Replicated defines the data distribution strategy:
- Replicated — Every cache node stores a full copy of all data
- Distributed — Data is distributed across cluster nodes
Copies defines the number of data copies used in Distributed mode.
For example, with 3 cache nodes and Copies set to 2, each node stores approximately 66% of the data. This ratio adjusts automatically based on node count and copy settings to optimize memory usage while preserving redundancy.
Hazelcast and Apache Ignite
Hazelcast and Apache Ignite are dedicated computing platforms that run on separate servers rather than inside Java application memory.
Selecting either option requires configuring:
- Host
- Port
The Host field can contain multiple boot nodes used for cluster discovery.
Hazelcast allows RAM from multiple servers to be combined into a single virtual space and includes built-in Stream Processing for real-time data handling.
Apache Ignite provides Native Persistence, allowing data storage on disk in addition to RAM. It also supports full ANSI-99 SQL for complex queries and JOIN operations.
Serialization Type
Serialization Type defines how data is packaged for transmission between cluster nodes.
The selected serialization method affects communication speed and resource overhead.
Available options include:
- Native — Uses the default serialization method of the selected cluster provider
- Kryo — High-speed third-party framework recommended for heavy production traffic
- Java Serialization / JBoss Marshalling — Alternative compatibility-focused methods with larger packet sizes
Core Cluster Settings
Cluster Name is a unique identifier, such as ussdgw, used by nodes to discover one another and rebalance cluster data.
Acquire Timeout defines the maximum time, in milliseconds, that a node waits to gain access to shared data.
Termination Timeout defines the grace period for task completion during node shutdown.
Command Timeout defines the maximum execution time for administrative commands across the cluster.
Summary
Clustering provides the foundation for platform scalability and reliability. Whether using embedded Infinispan or dedicated Hazelcast and Apache Ignite deployments, selecting the appropriate cache and serialization configuration ensures the system is prepared for high-availability and high-traffic environments.
Start innovating with Mobius
What's next? Let's talk!